
by Dr Kenneth Ban
Senior Lecturer, Department of Biochemistry
The practice of medicine continues to evolve in its quest to improve the prevention, diagnosis and treatment of diseases. The practice of medicine now adopts a rational approach grounded on our scientific understanding of the human body and how it interacts with the environment.
Technological advances in the current Digital Age allow healthcare and clinical decision-making recommendations to be synthesised from different sources of information, ranging from patient case reports to randomised controlled clinical trials and large scale population studies. This evidence-based approach has become the backbone of modern clinical practice, driving steady improvement in healthcare outcomes for patients and the population.
Today, the practice of medicine is poised for another transformation, catalysed by the increasing use of technology to digitalise and store healthcare information. Patient records and laboratory results are no longer paper-based but encoded as electronic health records accessible to healthcare professionals, who can then query and retrieve relevant information in a timely manner to make informed clinical decisions.
Besides facilitating access to patient records and results, this accelerated digitalisation of healthcare data enables new datadriven approaches based on the remarkable progress in the emerging fields of data science and machine learning. Digitalised healthcare data can be analysed computationally at scale to identify patterns that would otherwise be missed by conventional inspection, revealing new insights to improve healthcare outcomes.
Given this inexorable shift towards data-driven medicine, how can we equip our future doctors with the necessary competencies to remain top-class?
To provide our medical students with foundational knowledge in healthcare-focused data science, a team of educators from the Medical Sciences Cluster (MSC) and the Academic Information Office (AIO) of the National University Health System (NUHS), collaborated to conduct a five-day Introductory Health Informatics workshop for Phase I and II medical students in May 2019.
This pilot workshop was designed to introduce students to informatics and the principles of organising, querying, cleaning, and visualising data through a guided series of hands-on, practical sessions (Figure1). The workshop culminated in a mini-datathon that allowed students to use their newly-acquired skills to investigate a healthcare dataset.

Students presenting the outcomes of their group discussions.
Dr Ling Zheng Jye from AIO at NUHS began the workshop by introducing the broad principles of informatics. He led a series of group exercises requiring the students to define a health-related question, design appropriate survey questions to capture the relevant data, and finally to survey one another to obtain data for analysis. These exercises illustrated how defining a question determines what data needs to be captured, and the types of data collected and how the organisation of data determines how they can be used for analysis.
Building upon these core principles, I introduced students to key concepts regarding the handling of data. Students learnt about the relational data model and how to organise data in different forms so as to minimise errors and repetition. They then applied their learning through handson work to reorganise a healthcare dataset into a form suitable for database storage.
Next, students learnt the fundamentals of querying and retrieving data, using a standard programming language for relational databases called Structured Query Language (SQL), as well as an emerging standard for healthcare data exchange, called Fast Healthcare Interoperability Resources (FHIR). They completed a series of tasks that required them to retrieve relevant data from simulated healthcare databases hosted at the Medical Sciences Cluster.
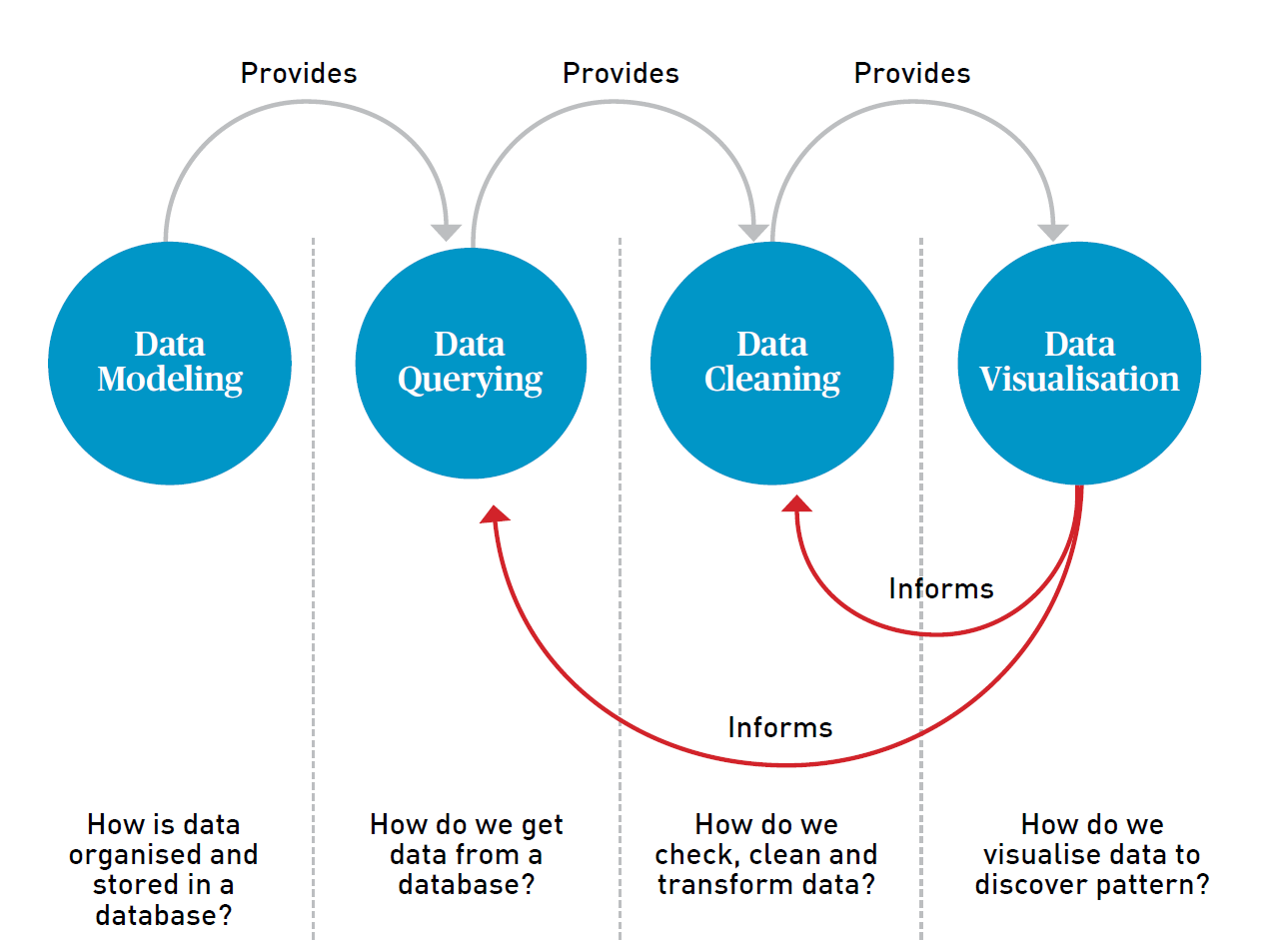
Figure 1
Following data retrieval, students verified the integrity of their data using a set of guidelines, including the necessary cleaning to transform data prior to analysis. Using an infectious disease outbreak dataset from a public database, students were guided to use a software tool (OpenRefine) to detect inconsistencies and correct anomalies in the dataset. This experience showed students that even curated datasets may contain anomalies that need to be checked, cleaned, and verified before they can be analysed.
To conclude the students’ preparation for the mini-datathon, Ms Shikha Kumari, Ms Pamela Lim, and Ms Lin Shuting from AIO at NUHS taught students how to use data visualisation as an approach to discover patterns and formulate hypotheses. They used the Tableau platform for quick exploratory analysis of a dataset to discover patterns, and the students practised using Tableau to visualise the data in different forms.
The final activity, the mini-datathon, enabled students to synthesise their learning: they used Tableau to explore a healthcare dataset, identified an observation of interest and formulated plausible hypotheses accordingly.
The workshop concluded with a talk by Dr Ngiam Kee Yuan, Group Chief Technology Officer of NUHS. A pioneer in the application of artificial intelligence and machine learning for healthcare in Singapore, Dr Ngiam gave an exciting overview of NUHS projects that leverage clinical data to make predictions as an aid to clinical decision making.
This introductory workshop, which is intended for all Phase I students, will form the foundation for a longitudinal track in Health Informatics. Workshops currently in development for later Phases will incorporate statistical learning and address topics such as artificial intelligence and machine learning.
By equipping our students with the essential competencies to use data science for healthcare applications, the School aims to prepare students for the era of data-driven medical practice and empower them to be innovators, leveraging healthcare data to derive new insights to improve health and patient outcomes.